lr-notebook/
Thoughts on Lektor as a Research Tool
2016-02-08Attachments:




Better science will require better tools
Science moves forward when talented, highly skilled people do things that have never been done before. This is easier said than done. Anyone who's worked in a lab knows that even decades-old protocols don't usually work on the first few attempts.
 Every protocol in this book has been unsuccessfully attempted many times.
Every protocol in this book has been unsuccessfully attempted many times.
Lately there's been a lot of concern about scientific reproducibility. However, it's hard to find nuanced discussion* of the root causes of "failed" experiments, let alone any practical solutions that might improve the situation for the people who do the actual work (i.e. students and postdocs).
* one exception: [On Reproducibility and Clocks](http://www.ascb.org/on-reproducibility-and-clocks/) by Peter Walter
There's always a trade-off between doing something new and teaching others what you recently learned. The biggest advances are often totally unexpected. Thus, positive results are often reported as a form of post hoc storytelling. Thanks to the "curse of knowledge", it's common to omit details that long ago became muscle memory for the authors, and even their highly specialized peer reviewers.
Policies + Tools
Policy incentives that encourage better reporting probably won't hurt, but they also won't magically make anything easier. If we truly want to improve scientific reproducibility, I suspect we need to complement the retroactive storytelling with new tools that lower the barrier to keeping track of detailed information as it is generated. A lot of information that might be useful for reproducing experiments is not easily captured as part of the normal research process, but if we can make collecting and sharing data easier, then perhaps we can start to imagine funding & publishing policies that go much further in making our research more accessible (and thus more reproducible).
Lektor
I believe a new web publishing system called Lektor has tremendous potential to upgrade the way researchers manage and share data. To understand why, I'll try to explain how I understand it in the context of amateur online publishing.
Web publishing has never been easy
Since the early days of the web, setting up and maintaining a website required a lot of technical expertise. Content needed to be coded in html. The html files needed to be hosted on a web server. Content changes were typically synchronized with the server via an FTP client. Many people worked without file version control, and mistakes could be costly. Thus, you needed at least one technical person somewhere in the loop, and if you couldn't hire one, you had to become one yourself.
Content Management System (CMS) era

wordpress.com
By the early 2000s, various new tools were developed to facilitate various steps of the publishing process. Content management systems (“CMS”) like Drupal and Wordpress were created. CMSs are similar to a wiki, in that they attempt to make it possible for non-programmers to create, edit, or delete content through a web-based admin interface. However, the complexity didn't disappear—it was simply shifted over to the system administrator, who now had to maintain a web server, plus server-side CMS software, and a database.
The dedicated server software needed be running at all times. You needed to pay for hosting, and you need a sysadmin somewhere in the loop who knows what they are doing. Servers typically need to be constantly patched with security updates, etc. Behind the scenes, the server runs its own database, and every time someone visits the website, the server has to query the database, get the necessary information, and convert it into html, and send it back to the visitors web browser. That works fine if there is little traffic on the site, but if there is ever a huge spike in traffic the server may have to respond to thousands of requests per second which can bring down the entire site (This used to be called slashdotting). It is possible to do "caching”, but it is typically complicated and hard to get right.
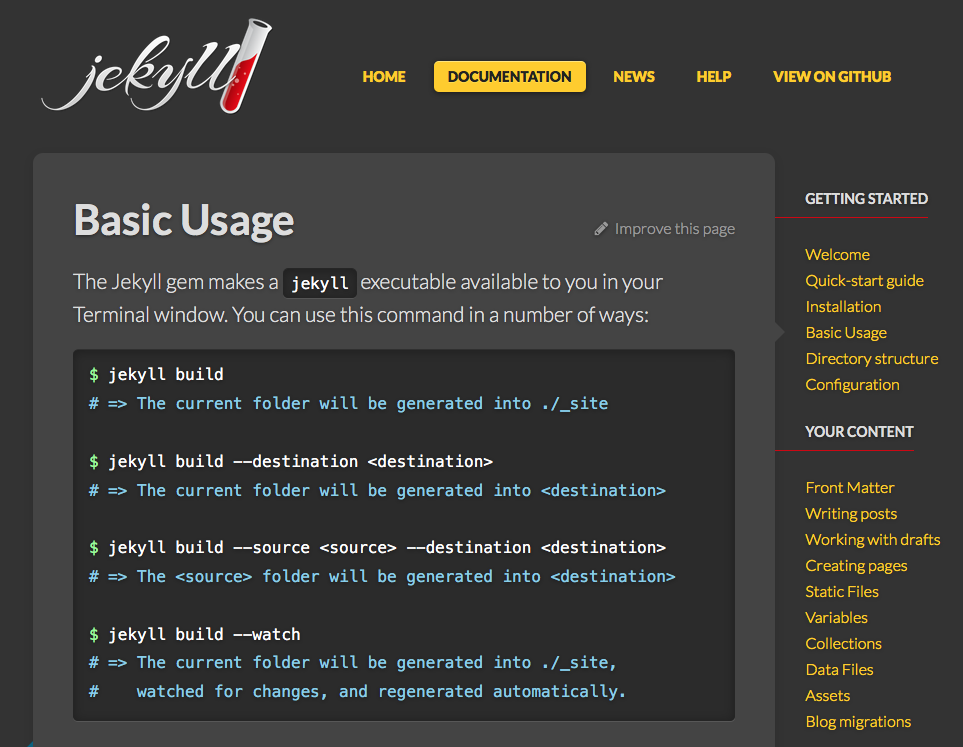
Static Site Generators

jekyllrb.com
In the mid- to late-2000s, the tools evolved a bit further. Another type of tool was called a static site generator. Instead of dynamically building every page in response to a visitor on the site, a set of scripts pre-complies everything into html once. This meant that files alone could again be hosted on a dedicated web server, just like before. Because there is no database, it was pretty simple to host on an http server, and many companies began offering this kind of hosting service for free (e.g. github pages).
Still, the complexity is not eliminated. Unfortunately, it shifted from the sysadmin back to the content creators. You can’t just log into an admin interface via the website anymore, but instead need to learn how to update the content and sync it with the hosting platform, probably using some kind of version control which is quite fragile. Definitely a downgrade from Drupal or Wordpress from the user perspective.
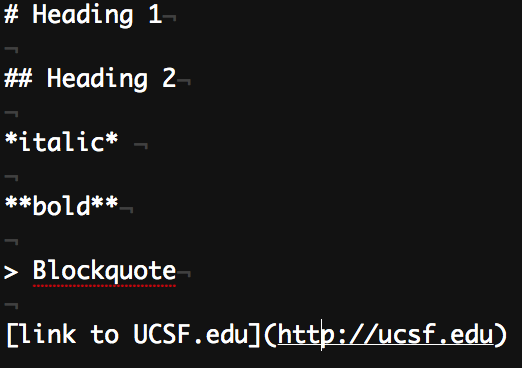
Quick aside: Markdown
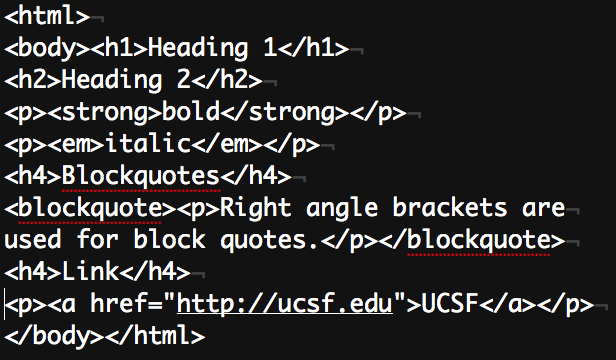
The language also evolved. In the mid-2000s markdown was created as a simplified form of html that is more human readable. Here are two examples content formatted with html and markdown that will ultimately display identically browser (since markdown just gets compiled into to html anyway).
 |
| |
| |
|:-:|:-:|:-:|
|html|markdown|output|
|
|:-:|:-:|:-:|
|html|markdown|output|
Markdown was popularized in part due to Jekyll + Github Pages... at least I think that's how I first encountered it. (Similar "lightweight" markup languages like reStructuredText and AsciiDoc predated markdown by several months but didn't take off.) It's now widely supported by modern web publishing tools.
Next up: Hybrid CMS/Static site generators
It seems the third stage in the evolution of the web publishing ecosystem are tools that seem to avoid the trade-off between client-side and server-side complexity by handling everything. The most exciting tool in this regard is called Lektor, created by Armin Ronacher. It seems there are somewhat similar tools such as grav.
The App
There are several things that are exciting about Lektor. First, it's an app. Now anyone who can run an OSX app can also run a web server. It works locally with flat files, so nothing needs to be synchronized with a remote server (though it can be configured to build & remotely deploy a static site).
 |
| |:-:|:-:|
|The Lektor app|Example Page|
|:-:|:-:|
|The Lektor app|Example Page|
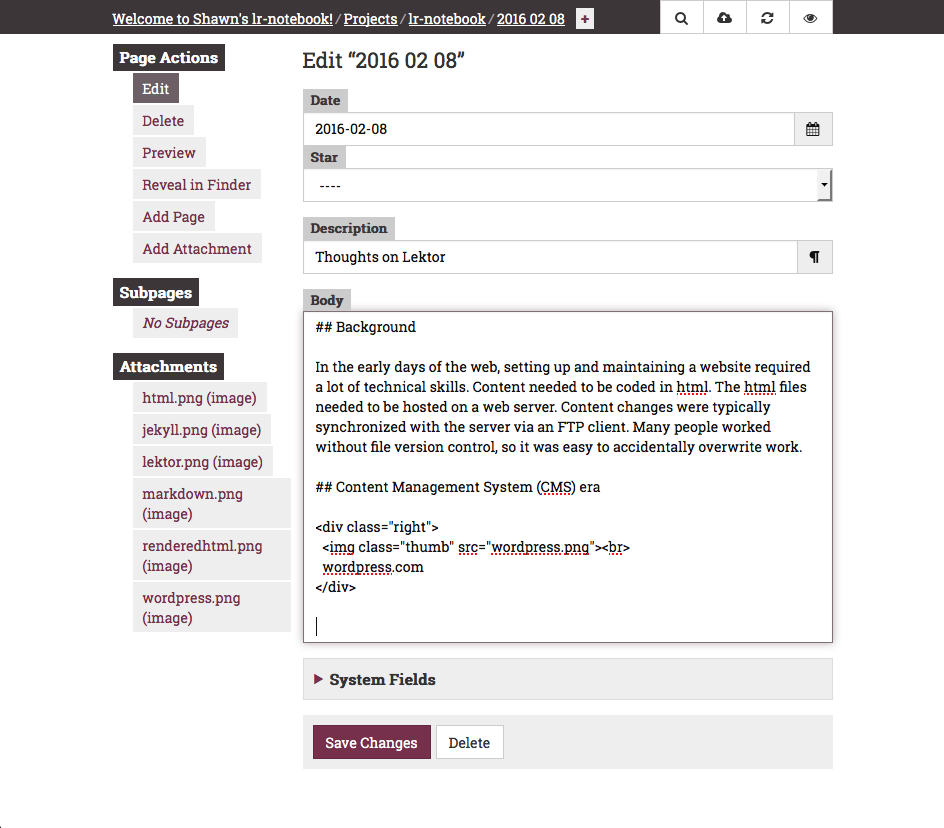
The CMS
The Lektor server includes a CMS (or wiki)-like admin interface that is easily accessed through the browser (the admin button is in the top right of every page). This makes it very easy to make simple changes to pages as you're browsing. In the future if a WYSIWYG markdown editor is included, it might be even for users who don't wish to use Markdown to format and style their content.
 |
|:-:|
|The admin UI|
|
|:-:|
|The admin UI|
I was very curious about how this is achieved, and after digging around the source and it turns out Lektor leverages another tool previously developed by Ronacher called click. Another bonus is that html template "framework" jinja is Python-based, which is very nice to work with.
A personalized, interactive view of the filesystem (!)

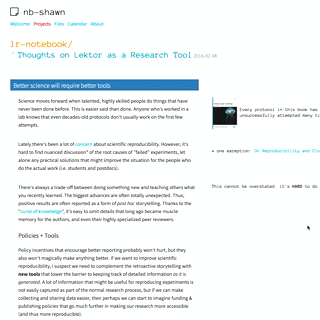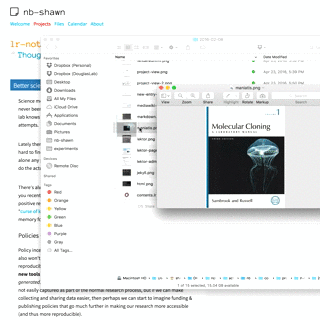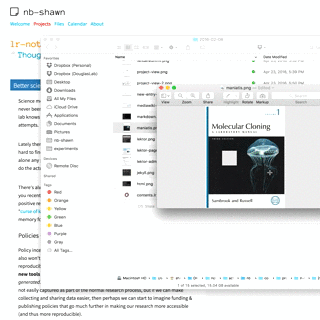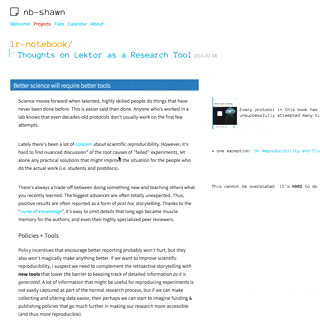
One of the most frustrating things about modern GUI-based operating systems is the constant overhead of finding and navigating to files. Getting work done requires leveraging diverse resources that are somehow always entropically scattered across virtual time and space. Thus, the thing that made me most excited when I first started playing with Lektor was the possibility of embedding JavaScript in html templates that would talk to the server API to perform file system operations (e.g. revealing, creating or editing files).
Since I can open files from the browser, I can now quickly edit it using a native tool (such as Photoshop), and then save it. Lektor will simply work in the background to rebuild all affected pages.

Additionally, thanks to Lektor it's now worthwhile to write my own filesystem views in html+css! For example I can build a page that shows me thumbnails of every single image in a project since day 1. Some example project pages on the right - dozens or hundreds of thumbnail images can be quickly scanned when trying to find something.
Overall Lektor is a very exciting advance in web development, thanks to amazing work by Ronacher.
Outlook
I've been working the last few months to build a new lab notebook using Lektor. If you're reading this at sdouglas.github.io/lr-notebook/, then you're looking at the deployed static version of that work.

I'll be the first to admit that the current layout of the notebook entries is highly personalized to my own tastes, and still unfinished. But I think the potential is there. Lektor provides a solid foundation for developing tools that facilitate better record keeping and sharing. Of course, new tools we create are only likely to be adopted if they let us continue to work with files and folders like we're used to. Dropbox was like this, which made it such a seamless upgrade.
It may seem obvious when you say it aloud, but I think it's very useful to start thinking about everything we do as researchers in terms of ultimately publishing to the web, rather than to journals. Then we might also begin to realize that we needn't always constrain ourselves to generating simulated pieces of paper, and begin to explore the possibilities that dynamic media can offer.